웹 크롤링을 배우기 전에 웹에 대해 먼저 찾아보자
웹은 Client와 Server로 이루어져 있다.
Client는 브라우저를 통해 Server에 데이터를 요청하는데 이를 Request라고 한다.
Server는 들어온 요청에 대해 알맞은 데이터를 Client로 전송하는데 이를 Response라고 한다.
- Client - Request : Browser를 사용하여 Server에 데이터를 요청
- Server - Response : Client의 Browser에서 데이터를 요청하면 요청에 따라 데이터를 Client로 전송
이러한 return은 브라우저에서 하용하는 주소의 형태로 오는데 이를 URL이라 한다.
우리가 말하는 URL은 Uniform Resource Locator의 약자로 각각 항목에 따라 주소를 구성하게 된다.
HTTP의 Request 방식이 Response 받은주소의 의미는 다음과 같다.
| http:// | Protocol | /main/ | Path |
| News | Sub Domain | read.nhn | Page ( File ) |
| naver.com | Primary Domain | mode=LSD | Query |
| 80 | Port | #da_727145 | Fragment |
전체적인 웹의 구조는 Client에서 Internet을 통해 Server로 Request를 요청한다.
서버는 이를 받아 WAS( Web Application Server )에서 DB를 통해 데이터를 TXT의 형태로 전달받아 Internet을 통해
Client 즉 Browser에 전달한다. 우리가 웹으로 보는 이 페이지도 이러한 과정을 갖게된다.
여기서 발생하는 트래픽은 Server에서 감당하는데 데이터 사용에 대해 Server에서 계속 비용을 내고있는 것이다.

Internet은 컴퓨터로 연결하여 TCP/IP 프로토콜을 이용하여 정보를 주고 받는 컴퓨터 네트워크이다.
해저케이블을 사용하여 전세계 컴퓨터에 접속하고있다.
우리가 사용하는 wifi또한 일정한 범위 안에서 무선으로 사용하지 공유기는 유선 인터넷 선으로 연결되어있고
아래 사진과 같은 해저케이블을 통해 자료가 전달된다.
예를들어 서울에서 미국 켈리포니아에 자료를 전송한다고 할 때, 인터넷 선을 통해 전달하기에 cost가 많이
발생한다.
크롤링을 이해하기 위해 추가로 알아두면 좋은 것을 정리한 것이다.
<HTTP의 Request 메서드는 Get방식과 Post방식이 있다.>
- Get
- URL에 Query 포함
- Query(데이터) 노출, 전송 가능 데이터 작음
- Post
- Body에 Query 포함
- Query(데이터) 비노출, 전송 가능 데이터 많음
<HTTP Status Code >
Client와 Server가 데이터를 주고 받은 결과 정보
- 2xx - Success - 성공에 관한 정보
- 3xx - Redirect - 요청을 완료하려면 추가적인 작업이 필요함(페이지 이동)
- 4xx - Request Error - 보통 404라고 많이 경험한 Request과정에서 에러
- 5xx - Server Error - Server의 문제로인해 Response하지 못하는 에러
<Cookie, Session, Cache>
- Cookie
- Client의 Browser에 저장하는 문자열 데이터
- 사용예시 : 로그인 정보, 내가 봤던 상품 정보, 팝업 다시보지 않음 등
- Session
- Client의 Browser와 Server의 연결 정보
- 사용예시 : 자동 로그인
- Cache
- Client, Server의 RAM(메모리)에 저장하는 데이터
- RAM에 데이터를 저장하면 데이터 입출력이 빠름
<Web Language & Framework >
- Client (Frontend)
- HTML, CSS - Bootstrap, Semantic UI, Materialize, Material Design Lite
- Javascript - react.js, vue.js, angular, jQuery
- Server (Backend)
- Python - Django, Flask, FastAPI
- Java - Spring
- Ruby - Rails
- Scala - Play
- Javascript - Express(node.js)
크롤링이 여러 페이지를 이동하며 데이터를 수집한다면 스크레핑은 틍정 데이터를 수집하는 작업이다.
< Scraping & Crawling >
- Scraping
- 특정 데이터를 수집하는 작업
- Crawling
- 웹서비스의 여러 페이지를 이동하며 데이터를 수집하는 작업
- spider, web crawler, bot 용어 사용
[ 웹페이지의 종류 ]
- 정적인 페이지 : 웹 브라우져에 화면이 한번 뜨면 이벤트에 의한 화면의 변경이 없는 페이지
- 동적인 페이지 : 웹 브라우져에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지

페이지가 정적인지 동적인지 알아보는 방법은 간단하다 화면에서 구성된 요소를 클릭했을 때 페이지가 새로고침된다면, 즉 페이지의 URL이 바뀐다면 동적인 페이지이고 새로고침 되지 않는다면 정적인 페이지 이다.
두 페이지 모두 HTML을 활용하지만 JSON의 경우 페이지의 한 부분이 다른 URL을 활용한 부분적인 요소로 들어간다.
python에서 데이터를 분석할 때에도 다음과 같은 차이가 있다.

우선 response하는 과정에서 돌아오는 타입이 각각 JSON과 HTML로 다르다.
다른 데이터 타입으로 인해 북석하는 방법에도 차이가 있다.
requests 이용
- 받아오는 문자열에 따라 두가지 방법으로 구분
- json 문자열로 받아서 파싱하는 방법 : 주로 동적 페이지 크롤링할때 사용
- html 문자열로 받아서 파싱하는 방법 : 주로 정적 페이지 크롤링할때 사용
selenium 이용
- 브라우져를 직접 열어서 데이터를 받는 방법
크롤링 방법에 따른 속도
- requests json > requests html >>>> selenium
Web Scraping / Crawling
이번에는 동적페이지에서 Web Scraping / Crawling을 하는 방법에 대해 알아보자.
먼저는 scraping으로 하나의 데이터를 가져와보자.
국내 증시에 들어가 자료를 살펴본다.
우리가 알고싶은것은 현재 날짜에 따른 코스피 지를 알기 원한다.
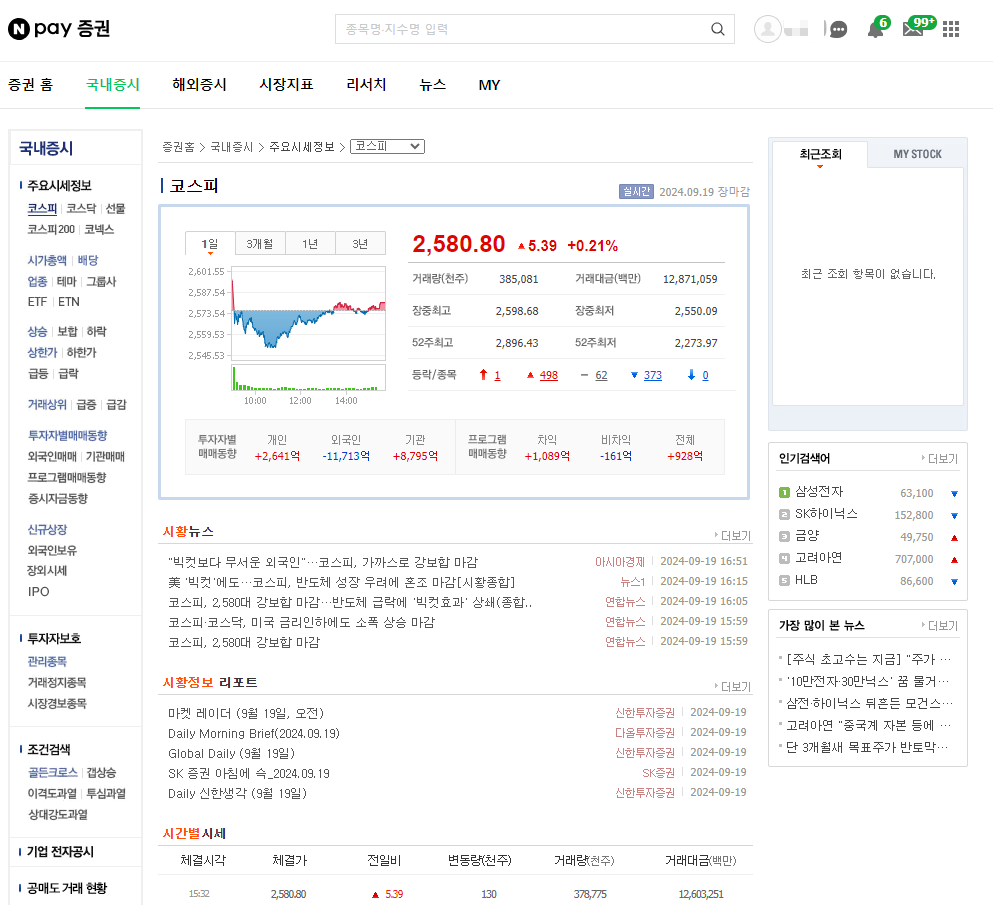
F12를 눌러 개발자 도구를 활성화 시킨다.
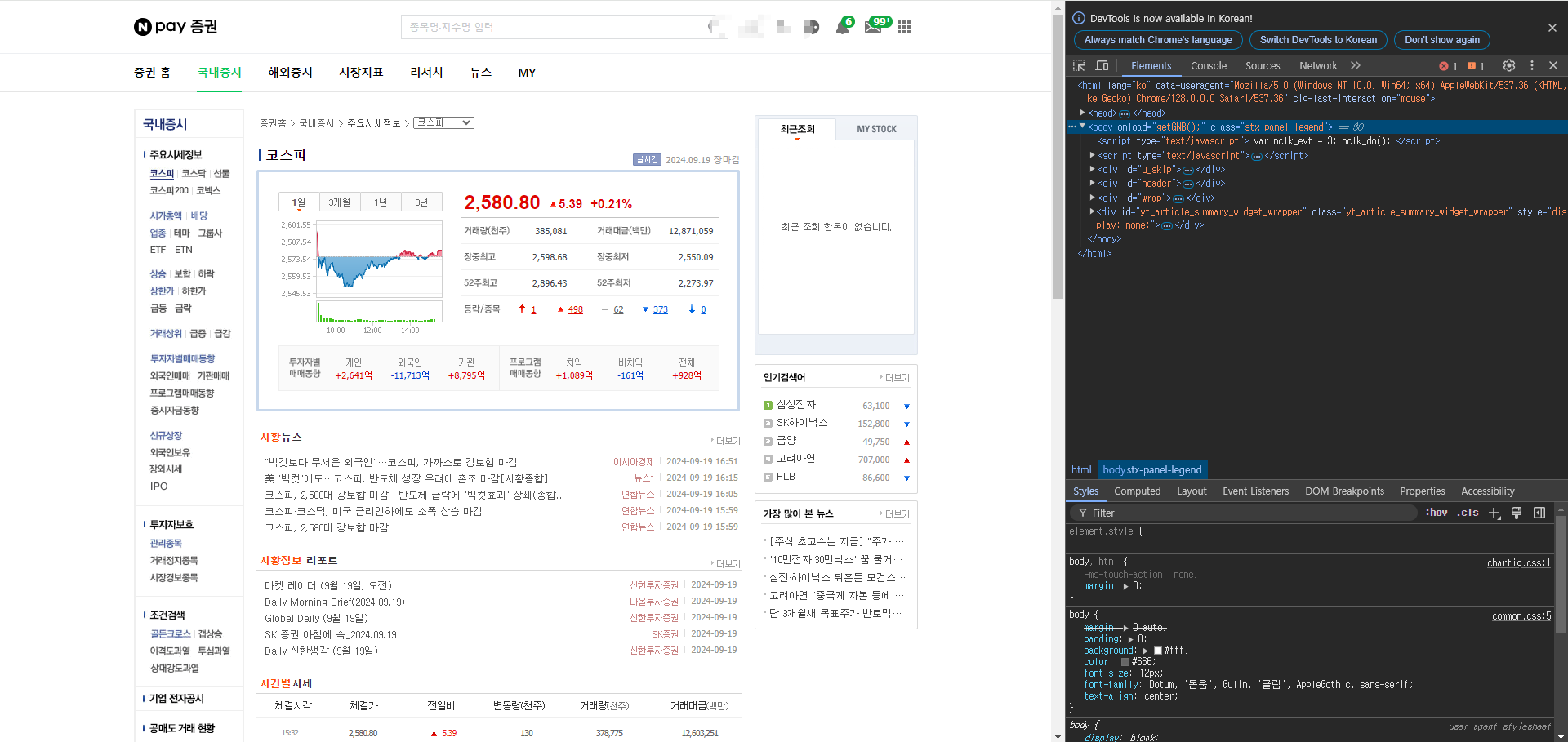
화살표 표시를 선택하고 화면에서 원하는 곳을 클릭하 구성된 HTML파일의 요소를 바로 확인할 수 있다.


휴대폰 모양이 있는 칸을 눌러주면 다음과 같이 화면이 변한다.
이때 주소창을 클릭하여 Enter를 누르면 모바일 화면으로 볼 수 있다.
모바일 환경에서 국내에 코스피를 선택해준다. 그리고 스크롤을 내려 일별 시세를 확인하였다.



개발자툴에서 Network를 선택해준다. 그리고 Clear버튼으로 네트워크 기록을 지워준다.

그리고 하단에 더보기를 눌러주면 넷트워크 활동이 감지된다. 여기서 GET방식으로 Request를 하였고
Status Code도 200으로 정상적인 Response가 이루어 진것을 확인하였다.
그럼 우리는 Request URL을 복사하여 활용해 보도록 하자.

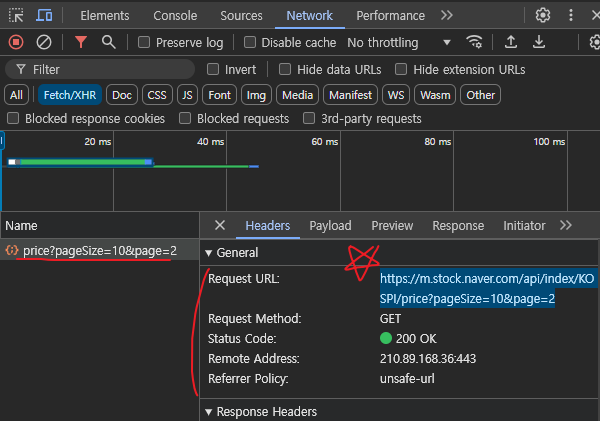
저 URL을 열어보면 다음과 같이 딕셔너리의 형태로 자료가 저장되어있는것을 확인할 수 있다.
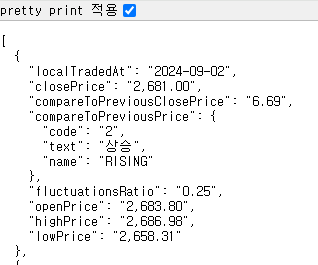
jupyter lab / notebook을 활용하여 데이터를 확인해보겠다.
먼저 requests와 pandas를 import해준다.
import requests
import pandas as pd
url을 지정해준다.
이때 다음과 같이 f스트링을 활용하여 주석처리되어있는 코드를 활용해도 된다.
직접 페이지 사이즈와 페이지를 조정해 얻고싶은 데이터를 얻을 수 있다.
# page_size, page = 60 , 1
# url = f'https://m.stock.naver.com/api/index/KOSPI/price?pageSize={page_size}&page={page}'
url = 'https://m.stock.naver.com/api/index/KOSPI/price?pageSize=10&page=2'
다음과 같이 requsets.get 메서드를 활용하여 저장하고 출력하면 <Response [200]>라는 결과를 확인할 수 있다.
만약 문법이 낯설다면 shift+tab을 활용하여 문법을 확인할 수 있다.
#shift + tab 하면 문법 사용법이 나옴
# 200은 success
response = requests.get(url)
print(response)<Response [200]>
데이터 타입을 살펴보면 다음과 같이 나온다.
type(response)requests.models.Response
.json을 활용하여 리스트 또는 딕셔너리의 형태로 자료를 저장해주고 이를 pandas의 DataFrame을 사용해 DF으로
만들어 준 결과 다음과 같은 자료를 확인할 수 있다.
data = response.json()
pd.DataFrame(data)
그럼 이제 날짜별로 종가를 확인하는 DF을 만들고 마무리 하도록 하자.
전체코드는 다음과 같다.
url = 'https://m.stock.naver.com/api/index/KOSPI/price?pageSize=10&page=2'
response = requests.get(url)
data = response.json()
df = pd.DataFrame(data)
df = df[['localTradedAt', 'closePrice']]
display(df)
다른 예제를 한번 살펴보자
이번에는 원달러 환율 데이터를 수집해보겠다.
네이버 > 증권 > 시장지표 순으로 이동하고 F12를 눌러 개발자모드는 활성화해 모바일 버전으로 이동하였다.
Network에서 기록을 모두 지워주고 환율을 볼수있도록 미국 USD를 클릭한다.

들어간 페이지에서 아래로 내리면 '일별 시세'에 더보기란이 있다.
클릭하고 어떤 URL로 데이터를 request하는지 확인한다.


여기서 얻은 url을 request.get해주서 response되는지 확인해보자
import requests
import pandas as pd
page = 1
url = f'https://m.stock.naver.com/front-api/marketIndex/prices?category=exchange&reutersCode=FX_USDKRW&page={page}'
response = requests.get(url)
response<Response [200]>
response code가 200임으로 잘 전달하고 전달 받았다는것을 확인 할 수 있다.
response.text를 찍어보면 우리가 이전에 봤던 text데이터와는 구조가 조금 다른것을 볼 수 있다.
url을 인터넷 주소에 찍어보니 다음과 같은 구성이였고, 우리가 원하는 'localTradedAt'와 'closePrice'는 result안에 있다.

이전에는 response전체에 .json을 해줬다면, 지금은 우리가 원하는 데이터를 갖고 있는 result만은 .json() 해준다.
그리고 'localTradedAt', 'closePrice'를 데이터프레임으로 만들어주고 확인한다.
data = response.json()['result']
df = pd.DataFrame(data)[['localTradedAt', 'closePrice' ]]
df다음과 같이 일별 달러 환률을 확인할 수 있다.
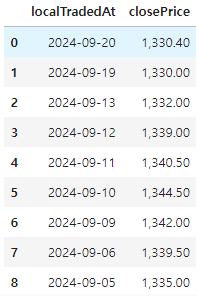
<시각화>
이번에는 코스피, 코스닥, 달러 환률을 확인하여 시각화 하고 어떤 관계를 갖고 있는지 확인해보자.
import requests
import pandas as pd
def stock_price(code = 'KOSPI', page=1, page_size=60):
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={page_size}&page={page}'
response = requests.get(url)
data = response.json()
return pd.DataFrame(data)[['localTradedAt', 'closePrice']]
def kosdaq_stock_price(code = 'KOSDAQ',page=1, page_size=60):
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={page_size}&page={page}'
response = requests.get(url)
data = response.json()
return pd.DataFrame(data)[['localTradedAt', 'closePrice']]
def exchange_rate(code = 'FX_USDKRW', page = 1, page_size = 60):
url = f'https://m.stock.naver.com/front-api/marketIndex/prices?category=exchange&reutersCode={code}&page={page}&pageSize={page_size}'
response = requests.get(url)
data = response.json()['result']
return pd.DataFrame(data)[['localTradedAt', 'closePrice' ]]
#데이터 수집
page_size = 30
kp_df = stock_price('KOSPI', page_size = page_size)
kd_df = stock_price('KOSDAQ', page_size = page_size)
usd_df = exchange_rate(page_size=page_size)
#데이터 전처리
kp_df['closePrice'] = kp_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
kd_df['closePrice'] = kd_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
usd_df['closePrice'] = usd_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
함수화를 통해 쉽게 호출하도록 하고 str형태로 저장되어 있는 데이터를 'lambda'를 활용하여 소수점을 없애고 float자료형으로 저장해준다.
<참고>
- apply 뒤에 오는 함수에 넣어서 결과 출력 그리고 다시 덮어쓰기
- 함수를 lambda로 작성 (parameter : return code) / , 제거 및 float형으로 변경
이렇게 만들어진 데이터를 시각화 하여 확인해보자
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 3))
plt.plot(kp_df['localTradedAt'], kp_df['closePrice'], label='kospi')
plt.plot(kd_df['localTradedAt'], kd_df['closePrice'], label='kosdaq')
plt.plot(usd_df['localTradedAt'], usd_df['closePrice'], label='usd')
plt.xticks(kp_df['localTradedAt'][::5])
plt.grid()
plt.legend()
plt.show()
이렇게만 보면 서로 어떤 관계를 갖고있느지 확인하기 어렵다.
그렇기 떄문에 데이터 스케일링을 통해 각각 자료의 가장 큰 값을1, 가장 작은값을 0으로 스케일링 해준다.
<데이터 스케일링>
- min max scaling

수식으로 확인해보면 가장 큰값과 가장 작은값은 각가 1과 0이 될 수밖에 없는 구조이다.
파이썬에서는 sklearn.preprocessing안에 minmax_scale을 사용하면 쉽게 구현할 수 있다.
from sklearn.preprocessing import minmax_scale
minmax_scale(kp_df['closePrice'])array([0.47509007, 0.34704066, 0.31930005, 0.30221307, 0. ,
0.0517756 , 0.11610911, 0.15908389, 0.31976325, 0.34704066,
0.77848688, 0.86273803, 0.82830674, 0.76639218, 0.90818322,
0.90519815, 0.95028307, 0.96922285, 1. , 0.96634071,
0.94318065, 0.82856408, 0.94626866, 0.6748842 , 0.55651055,
0.54004117, 0.38630983, 0.22316006, 0.28327329, 0.04518785])
모든 값들이 0 <= x <=1임을 확인할 수 있다.
이를 그래프로 확인하면 스케일링을 통해 한눈에 파악하기 쉬워진다.
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 3))
plt.plot(kp_df['localTradedAt'], minmax_scale(kp_df['closePrice']), label='kospi')
plt.plot(kd_df['localTradedAt'], minmax_scale(kd_df['closePrice']), label='kosdaq')
plt.plot(usd_df['localTradedAt'], minmax_scale(usd_df['closePrice']), label='usd')
plt.xticks(kp_df['localTradedAt'][::5])
plt.grid()
plt.legend()
plt.show()
<상관관계 분석>
상관계수를 통해 데이터 집합의 상관도를 분석해보자
- 상관계수의 해석
- -1에 가까울수록 서로 반대방향으로 움직임
- 1에 가까울수록 서로 같은방향으로 움직임
- 0에 가까울수록 두 데이터는 관계가 없음
데이터 전처리를 통해 코스피, 코스닥, 달러 환률을 하나의 DataFrame으로 만들어준다.
#데이터 전처리 merge
# kp_df
# kd_df
# usd_df
merge_df = pd.merge(kp_df, kd_df, on = 'localTradedAt')
merge_df = pd.merge(merge_df, usd_df, on = 'localTradedAt')
merge_df.columns = ['Date', 'Kospi', 'Kosdaq', 'Usd']
merge_df.head()
iloc를 사용하여 상관계수를 분석하면
merge_df.iloc[:, 1:].corr()
다음과 같은 상관계수를 확인할 수 있다.
그래프와 상관계수를 같이 보았을 때 다음과 같은 분석을 할 수 있다.
- 원달러 환율이 높으면 달러를 원화로 환전하여 코스피 지수를 구매한다.
- 원달러 환율이 낮으면 코스피지수를 판매하여 달러로 환전한다
이번 시간에는 Web과 Web Scraping / Crawling에 대한 개념과 요소, 간단한 예제를 살펴보았다.
이러한 방식을 사용하면 서버 비용을 N사에서 처리하게 되는데 N사에서는 제대로 서비스 하지 않는데 Server에서는
데이터를 처리했다고 요금을 청구한다. 이러한 방법을 사용하지 않고 API를 활용하여 Crawling하도록 하자.
'<프로그래밍> > [python-WebCrawling]' 카테고리의 다른 글
| Web과 Web Scarping / Crawling 3(응용) (0) | 2024.09.24 |
|---|---|
| Web Crawling5 (0) | 2024.09.23 |
| Web과 Web Scarping / Crawling 2(NAVER API) (1) | 2024.09.21 |