머신러닝 개념과 관련 용어
머신러닝 이해
인간의 개념은 머신의 데이터이다.
우리가 일정한 패턴을 통해 스스로 학습하는 과정을 컴퓨터에 적용했다고 비유할 수 있다.
간단한 패턴이라면 사람의 두뇌로 해결할 수 있지만, 복잡한 패턴을 일일히 분석하는건 힘들고 비효율적인 일이다.
문제 해결 순서
- 문제의 유형을 파악 > 알고리즘과 평가 방법을 선택 > 관련 함수를 사용해 모델링
지도학습
- 학습 대상이 되는 데이터에 정답을 준다.
- 규칙성, 즉 데이터의 패턴을 배우게 하는 학습 방법이다.
- 분류문제
- 적절히 분류된 데이터를 학습하여 분류 규칙을 찾는다.
- 규칙을 기반으로 새롭게 주어진 데이터를 적절히 분류하는것이 목적이다.
- 범주형 자료
- A일까? B일까 고민하는 문제
- 회귀문제
- 결과값이 있는 데이터를 학습하여 입력 값과 결과 값의 연관성을 찾는다.
- 연관성을 기반으로 새롭게 주어진 데이터에 대한 값을 예측하는것이 목적이다.
- 숫자형 자료 - 연속적인 숫자 예측
- 두 값 사이에 중간값이 의미가 있는가?
- 두 값에 대한 연산 결과가 의미있는 숫자인가?
- 얼마나 많이? 라고 질문을 던질 수 있는 문제
비지도 학습
- 정답이 없는 데이터 만으로 배우게 하는 학습 방법
- 클러스터링
- 데이터를 학습하여 적절한 분류 규칙을 찾아 데이터를 분류하는 것이 목적.
- 정답이 없으니 성능을 평가하기 어렵다.
- 군집화 - 비슷한것을 그룹으로 묶음
- 변환 - 쉽게 이해할 수 있는 형태로 데이터 표현
- 연관 - 서로 연관된 특징을 찾음
강화 학습
- 선택한 결과에 배해 보상을 받아 행동을 개선하면서 배우게 하는 학습 방법
용어정리
모델(model)
- 데이터로부터 패턴을 찾아 수학식으로 정리해 놓는것
- 모델링(Modeling): 오차가 적은 모델을 만드는 과정
모델의 목적( 모델을 만드는 과정 -> 모델링)
- 샘플을 가지고 전체를 추정
- 샘플: 표본, 부분집합, 일부, 과거의 데이터
- 전체: 모집단, 전체집합, 현재와 미래의 데이터
- 추정: 예측, 추론
독립변수(원인), 종속변수(결과)
- x값이 변함에 따라 y값이 변한다. 라고 할때
- 독립변수를 x, 종속변수를 y로 표시함 ex) y = ax + b
평균과 오차
- 통계학에서 사용되는 가장 단순한 모델 중 하나가 평균이다.
- 관측값(=실젯값)과 모델 예측값의 차이: 이탈도(Deviance) → 오차
- 범주에서는 최빈값(가장 많이 나온 값)으로 예측할 수 있다.
데이터 분리
- 데이터 셋을 학습용 검증용 평가용 데이터로 분리함
- 실전에서 평가용 데이터는 별도로 제공되는 데이터일 경우가 많다.
- 검증용 데이터로 평가 전에 모델 성능을 검증해 볼 수 있다.(튜닝시 사용)
- x(독립변수)와 y(종속변수)를 분리 - DF의 열을 분리 : DF.drop(열이름, axis = 1) / DF.loc[ ]
- 학습용, 편가용 분리 - DF의 행을 분리 : train_test_split(x, y, test_size = float) : size의 최대크기는 1
과대적합과 과소적합
- 과대적합(Overfitting)
- 학습 데이터에 대해서는 성능이 매우 좋은데, 평가 데이터에 대해서는 성능이 매우 좋지 않은 경우
- 학습 데이터에 대해서만 잘 맞는 모델 → 실전에서 예측 성능이 좋지 않음
- 과소적합(Underfitting)
- 학습 데이터보다 평가 데이터에 대한 성능이 매우 좋거나, 모든 데이터에 대한 성능이 매우 안 좋은 경우
- 모델이 너무 단순하여 학습 데이터에 대해 적절히 훈련되지 않은 경우
모델링 코드 구조
Scikit-Learn(사이킷런)
불러오기 - 사용할 알고리즘과 평가를 위한 함수 import
1. 알고리즘
- from sklearn.linear_model import LinearRegression - 회귀
- from sklearn.neighbors import KNeighborsClassifier - 분류 (0, 1로 분류)
- from sklearn.tree import DecisionTreeClassifier - 분류 (str 형태의 분류)
2. 평가
- from sklearn.metrics import mean_absolute_error - 회귀
- from sklearn.metrics import accuracy_score - 분류
3. 선언하기 - 사용할 알고리즘용 함수로 모델 선언
- model = LinearRegression() - 회귀
- model = KNeighborsClassifier() - 분류
- model = DecisionTreeClassifier() - 분류
4. 학습하기 - 모델.fit(x_train, y_train) 형태로 모델 학습 시키기
- model.fit(x_train, y_train)
5. 예측하기 - 모델.predict(x_test) 형태로 예측한 결과 변수로 저장
- y_pred = model.predict(x_test)
6. 평가하기 - 실젯값과 예측값을 평가 함수에 전달해 성능 평가
- mean_absolute_error( y_test, y_pred )
- mean_absolute_error( y_test, y_mean )
- y_mean = [ y_train.mean() ] * len(y_test) - 평균값으로 Base Model을 만들어 기본오차를 구함 -회귀
- mean_absolute_error( y_test, y_freq )
- y_freq = [ y_train.mode()[0] ] * len(y_test) - 최빈값으로 Base Model을 만들어 기본오차를 구함 -분류
모델링 예제
자료준비
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')
%config InlineBackend.figure_format = 'retina'
# 데이터 읽어오기
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/airquality_simple.csv'
data = pd.read_csv(path)
데이터 구조 확인
data.tail(2)
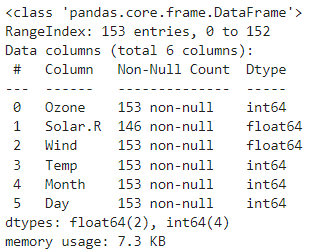
변수확인 - Solar.R에 결측치가 존재함을 확인
# 변수 확인 #결측치 확인 Solar.R
data.info()
통계 확인
# 기술통계 확인
data.describe().T

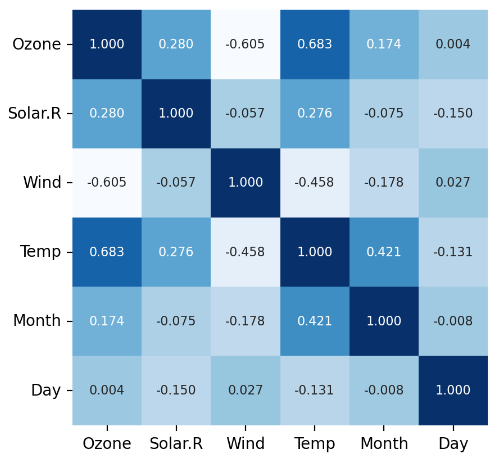
상관 관계 분석 및 시각화
# 상관관계 확인
data.corr(numeric_only = True).style.background_gradient()# 상관관계 시각화 Purples
sns.heatmap(data.corr(numeric_only = True),
annot = True, cmap = 'Blues',
cbar = False, square = True,
fmt = '.3f', annot_kws = {'size' : 8})
plt.yticks(rotation = 0) #y측
plt.show()
데이터 전처리
결측치 처리
# 결측치 확인
data.isna().sum()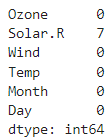
# 위에값으로 결측치 채우기 / 아래값, bfill()
data['Solar.R'] = data['Solar.R'].ffill()
# data.ffill(inplace = True)# 확인
data.isna().sum()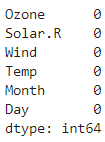
변수 제거
# 분석에 의미 없는변수 제거
drop_cols = ['Month', 'Day']
data.drop(columns = drop_cols, inplace = True)
# 확인
data.head(1)
x, y, 분리
알아내고자 하는것 = target = 오존 농도
# target 확인
target = 'Ozone'
# 데이터 분리
x = data.drop(target, axis = 1) #( columns = target)
y = data.loc[ :, target] #data['Ozone']
머신러닝을 위한 변수 생성
# 모듈 불러오기
from sklearn.model_selection import train_test_split
# 7:3으로 분리 중요함!!!
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 1)
#random_state = n 으로 같은 random값을 준다면 같은 결과를 줌 seed와 같은 원리
#만약 회귀가 아닌 분류라면stratify = y 를 활용하여 일정한 데이터로 분리
모델링
# 1단계: 불러오기
from sklearn.linear_model import LinearRegression #회귀
from sklearn.metrics import mean_absolute_error
# 2단계: 선언하기
model = LinearRegression()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test)
# 5단계: 평가하기
mean_absolute_error(y_test, y_pred)13.976843190385708
예측값과 실제값 비교 / 시각화
# 예측값과 실젯값 시각화 비교
print('실제값 :',y_test.values[:10])
print('예측값 :',y_pred[:10])실제값 : [24 18 97 47 34 22 66 18 69 27]
예측값 : [13.84003067 5.82919112 81.93563027 58.41267418 50.86150737 31.52971121
66.8083547 -8.56411529 50.2136544 39.13346172]
기본모델 오차와 비교
#기본 모델(Base Model) 오차
# 평가 데이터 행수 만큼 평균값 준비
y_mean = [y_train.mean()] * len(y_test)
print("MAE = ", mean_absolute_error(y_test, y_mean))
plot
plt.figure(figsize = (14, 4))
plt.plot(y_test.values, label = 'Actual')
plt.plot(y_pred, label = 'Predicted')
#plt.legend(['Actual', 'Predicted'])
plt.legend()
plt.show()
Graphvis
그래프를 좀더 시각적으로 좋게 볼 수 있다.
Graphvis > Downlod > 각자 환경에 맞는 버전 선택 > 기본 설정으로 설치
설치 후 설정
내pc > 속성 > 고급시스템 설정


환경변서 > path > 편집 > 찾아보기


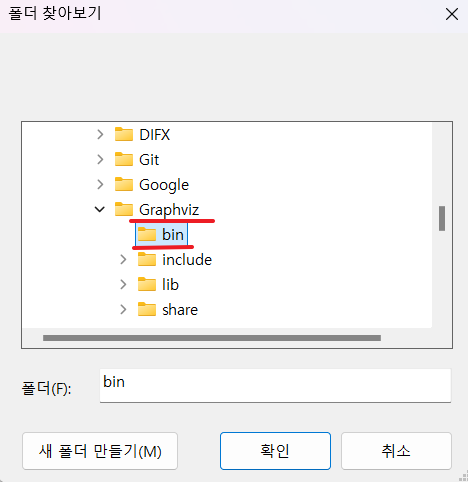
C드라이브 > Program Files > Graphviz > bin 선택후 확인
시스템 변수도 마찬자기로 진행 > 재부팅
'<프로그래밍> > [python]' 카테고리의 다른 글
| [python] 머신러닝의 기초3 (0) | 2024.09.30 |
|---|---|
| [python] 머신러닝의 기초2 (1) | 2024.09.27 |
| [python] 데이터 시각화2(단변량 분석) (1) | 2024.09.26 |
| [python] 데이터 시각화1(matplotlib 기초) (0) | 2024.09.10 |
| [python] pands 정리(+seaborn) / 데이터 전처리 (1) | 2024.09.06 |