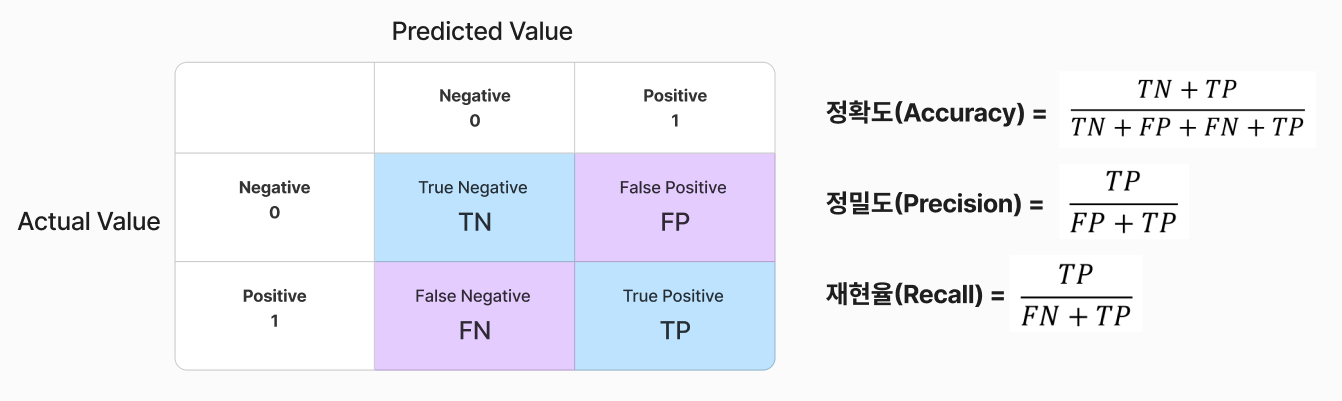
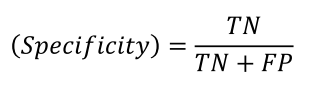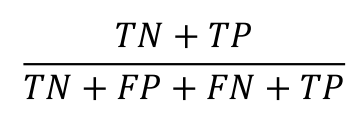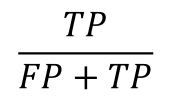기본환경
jupyter lab / notebook 이 아닌 google colaboratory를 활용한다.
파일을 google drive에 업로드하여 연결 앱에서 지정해주는데 없다면 다음과 같이 진행하여 설치해 준다.

딥러닝 학습 절차
- 가중치 초기값을 할당한다. (초기 모델을 만든다. / 초기값은 random하게 할당됨)
- (초기)모델로 예측한다.
- 오차를 계산한다. (loss function)
- 가중치 조절 : 오차를 줄이는 방향으로 가중치를 적절히 조절한다.(optimizer)
- 적절히 조절 → 얼마 만큼 조절할 지 결정하는 하이퍼파라미터 : learning rate (lr)
- 다시 처음으로 가서 반복한다.
- 전체 데이터를 적절히 나눠서(mini batch) 반복 : batch_size
- 전체 데이터를 몇 번 반복 학습할 지 결정 : epoch
딥러닝 모델링 : Regression
딥러닝 전처리 : 스케일링
Normalization(정규화) - 모든 값의 범위를 0 ~ 1로 변환
Standardization(표준화) - 모든 값을, 평균 = 0, 표준편차 = 1 로 변환
Dense
Input : Input(shape = ( , ))
- 분석단위에 대한 shape
- 1차원 : (feature 수, )
- 차원 : (rows, columns)
Output : Dense( n )
- 예측 결과가 1개 변수(y가 1개 변수)
- 이진분류 : activation = 'sigmoid' / 0과 1 사이의 확률값으로 지
- 다중분류 : activation = 'softmax '
Hidden Layer : Dense( n, activation = 'relu' )
- activation : 현재 레이어(각 노드)의 결과값을 다음 레이어(연결된 각 노드)로 어떻게 전달할지 결정/변환해주는 함수
- Hidden Layer에서는 : 선형함수를 비선형 함수로 변환
- Output Layer에서는 : 결과값을 다른 값으로 변환해 주는 역할
Hidden Layer에서 무슨 일이 일어나는가?
- 기존 데이터를 받아들임.
- (우리는 정확히 알기 어렵지만) 뭔가 새로운 특징(New Feature)을 만듬
- 특징은 분명히 예측된 값과 실제 값 사이의 오차를 최소화 해주는 유익한 특징일 것으로 생각.
- Hidden Layer에서는 기존 데이터가 새롭게 표현(Representation)
- Feature Engineering이 진행

Compile
컴파일(Compile)
- 선언된 모델에 대해 몇 가지 설정을 한 후 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
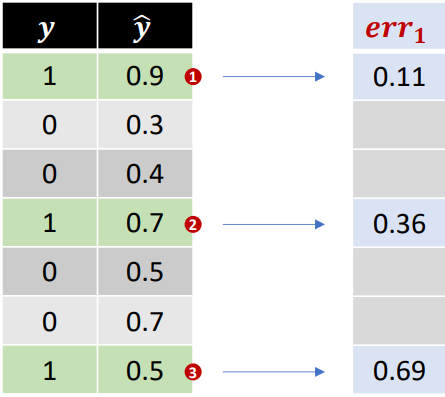
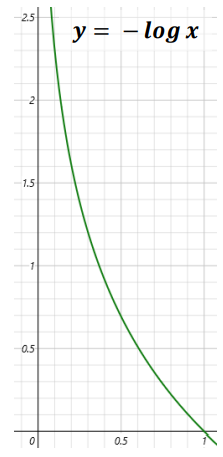
loss function(오차함수)
- Cost Function, Objective Function 과 같은(유사한) 의미
- 오차 계산을 무엇으로 할지 결정
- 회귀모델 : mse
- 분류모델 : cross entropy
optimizer
- 오차를 최소화 하도록 가중치를 업데이트하는 역할
- Adam - 최근 딥러닝에서 가장 성능이 좋은 Optimizer로 평가 됨.
- learning_rate - 업데이트 할 비율 / 기울기(gradient)에 곱해지는 조정 비율 (걸음걸이의 ‘보폭’을 조정한다고 표현)
학습
Epoch
- 주어진 train set을 몇 번 반복 학습할 지 결정
validation_split = 0.2
- train 데이터에서 20%를 검증셋으로 분리
batch_size
- 배치 단위로 학습(가중치 업데이트), 기본값 32
- 전체 데이터를 적절히 나눠서(mini batch)
.history
- 학습을 수행하는 과정 중에 가중치가 업데이트 되면서 학습 시 계산된 오차 기록
학습 곡선
- 모델 학습이 잘 되었는지 파악하기 위한 그래프
- 정답은 아니지만, 학습 경향을 파악하는데 유용.
- 각 Epoch 마다 train error와 val error가 어떻게 줄어들고 있는지 확인
바람직한 학습 곡선
- 초기 epoch에서는 오차가 크게 줄어듬.
- 오차 하락이 꺾이임.
- 점차 완만해짐 - 그러나 학습곡선의 모양새는 다양함
바람직 하지 않은 학습 곡선
Case 1

- 학습이 덜 됨
- 오차가 줄어들다가 학습이 끝남
- 조치 : 학습을 더! / epoch 수를 늘리거나 learning rate을 크게 한다.
Case 2
- train_err가 들쑥날쑥

- 가중치 조정이 세밀하지 않음
- 조치 : 조금씩 업데이트 / learning rate을 작게
Case 3
- 과적합

- Train_error는 계속 줄어드는데, val_error는 어느 순간부터 커지기 시작
- 너무 과도하게 학습이 된 경우
- 조치 - Epoch 수 줄이기
# 라이브러리 로딩
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Input
from keras.backend import clear_session
from keras.optimizers import Adam
#학습곡선 그래프 함수 만들기
def dl_history_plot(history):
plt.figure(figsize=(10,6))
plt.plot(history['loss'], label='train_err', marker = '.')
plt.plot(history['val_loss'], label='val_err', marker = '.')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.grid()
plt.show()
#데이터로딩
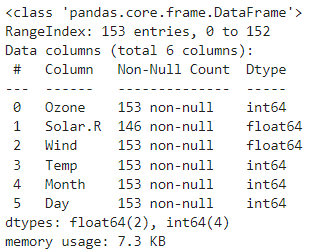
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/Carseats.csv'
data = pd.read_csv(path)
#데이터 준비
target = 'Sales'
x = data.drop(target, axis=1)
y = data.loc[:, target]
#가변수화
cat_cols = ['ShelveLoc', 'Education', 'US', 'Urban']
x = pd.get_dummies(x, columns = cat_cols, drop_first = True)
#데이터분할
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2, random_state = 20)
#Scaling
scaler = MinMaxScaler()
x_train = scaler.fit_transform(x_train)
x_val = scaler.transform(x_val)
#모델 설계
nfeatures = x_train.shape[1]
model = Sequential([Input(shape = (nfeatures, )), Dense(7, activation = 'relu'), #선형을 비선형으로
Dense(1)])
model.summary()
#컴파일 + 학습
model.compile(optimizer = Adam(learning_rate = 0.05), loss = 'mse')
result = model.fit(x_train, y_train, epochs = 40, validation_split= 0.2).history
#학습곡선
dl_history_plot(result)
#검증
pred = model.predict(x_val)
print(mean_absolute_error(y_val, pred))
딥러닝 모델링 : 이진분류 / 다중분
Output Layer
- 결과를 0, 1로 변환하기 위해 각 범주에 대한 결과를 범주별 확률 값으로 변환
- 이진분류 : activation = 'sigmoid'
- Loss Function : binary_crossentropy

- 다중분류 : activation = 'softmax' - 0~1사이 확률 값으로 변환
- Loss Function : sparse_categorical_crossentropy(정수 인코딩)
- Loss Function : categorical_crossentropy(one-hot 인코딩) / 기능적으로는 둘다 동일
'<프로그래밍> > [python]' 카테고리의 다른 글
| [python] 딥러닝 Function API / 시계열 데이터 (0) | 2024.10.15 |
|---|---|
| [python] 딥러닝 성능관리 (0) | 2024.10.14 |
| [python] 머신러닝의 기초3 (0) | 2024.09.30 |
| [python] 머신러닝의 기초2 (1) | 2024.09.27 |
| [python] 머신러닝의 기초 (0) | 2024.09.26 |